Tipos de redes neuronales
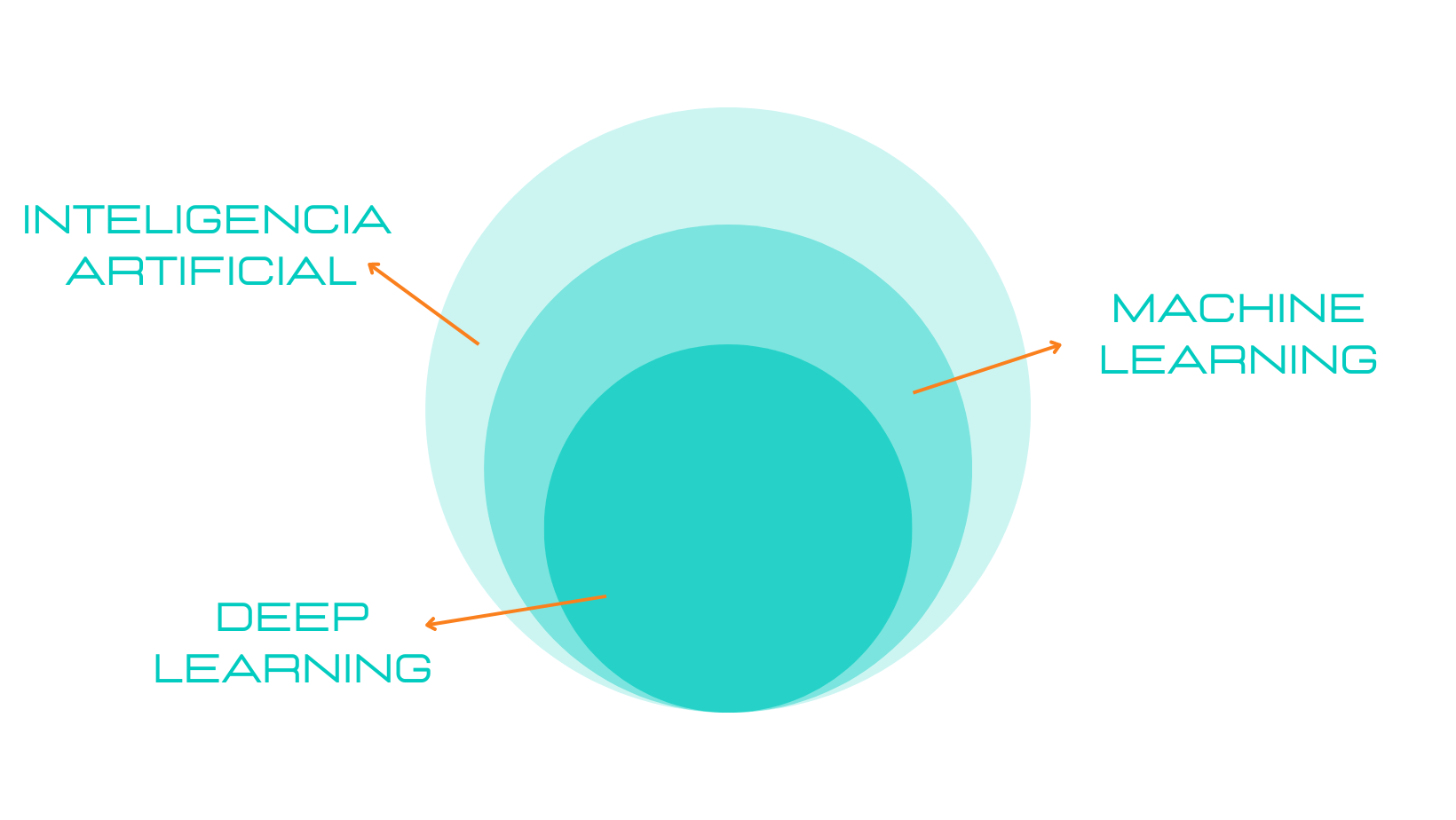
El futuro de la Inteligencia Artificial ha llegado.
Como concepto, el deep learning es bastante reciente. Se mencionaría por primera vez aproximadamente allá por el año 2000. No obstante, la idea de desarrollar redes neuronales para enseñar al modelo a tomar decisiones tiene ya varias décadas. En los años 80 se crearon las primeras redes neuronales, con resultados bastante decepcionantes, todo hay que decirlo.
Si quisiéramos dotar a un sistema de IA de la capacidad de análisis
de sentimientos y nos remontáramos a principios de siglo, lo abordaríamos como
un problema de clasificación de la polaridad de las palabras. Introduciríamos
en el dataset un conjunto de buenas y malas palabras y les asignaríamos una
puntuación a cada una de ellas. El sistema detectaría en la frase que debiera
analizar, el cómputo total de puntos del conjunto de buenas y malas palabras y
daría una valoración final de la oración determinando finalmente si el
sentimiento es positivo o negativo.
Una solución sencilla. Si. Pero con problemas. Veamos un ejemplo:
“Eres un tío genial para ser negro”.
El trasfondo de la oración es claramente negativo pero el modelo interpretaría un sentimiento positivo, ya que la valoración de palabras como “genial” sería positiva y no habría palabras con valoración negativa dentro de la frase. Y es que el sistema no era capaz de interpretar la ironía o el sarcasmo o juegos de palabras.
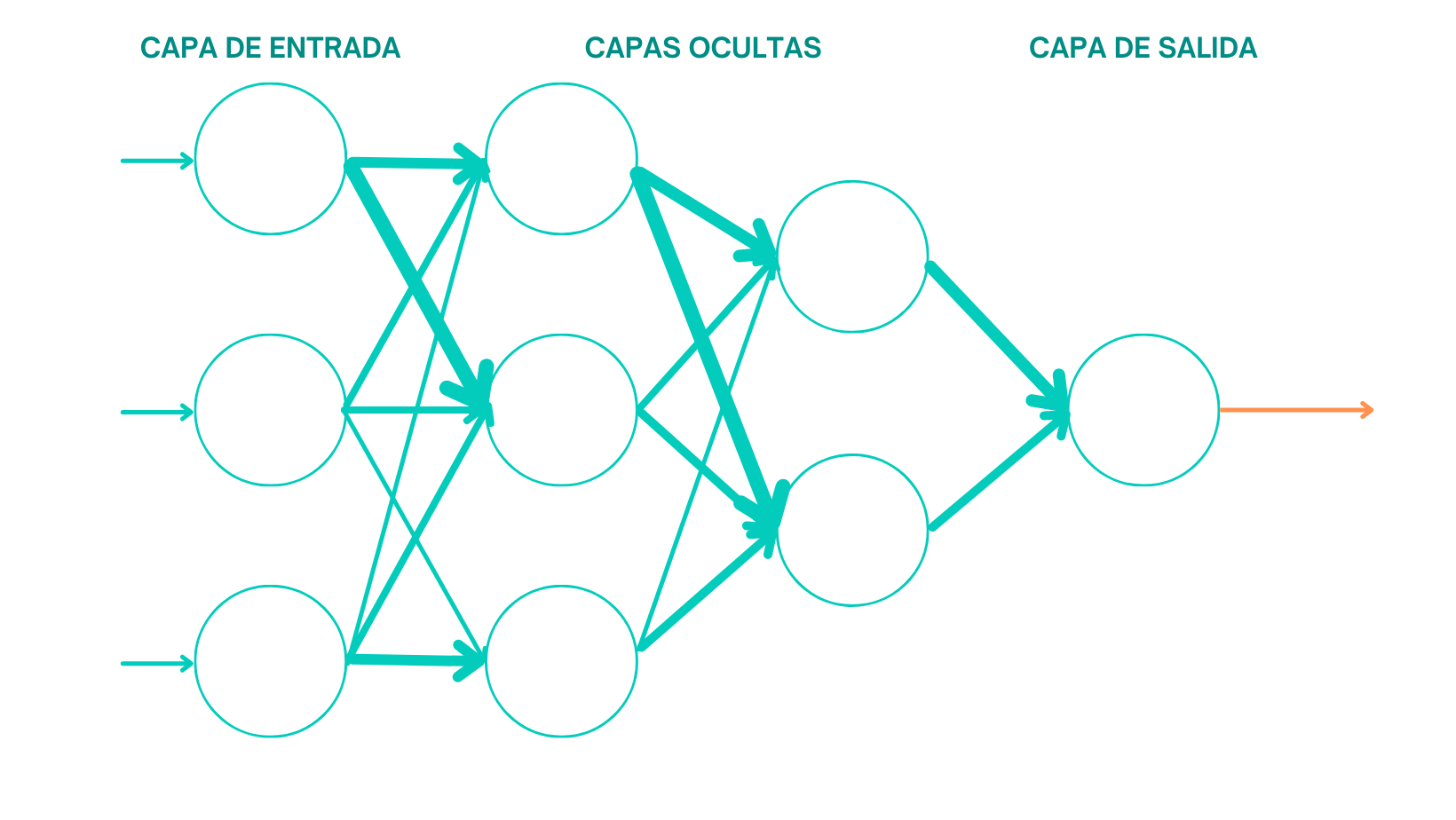
Las Redes Neuronales Recurrentes.
Si avanzamos hasta 2012, aproximadamente, estaríamos
avanzando hasta el verdadero comienzo de la era del Deep Learning y es que, durante
la última década hemos visto resucitar la carrera por una Inteligencia Artificial
que parecía haberse estancado.
Comenzaron a utilizarse redes neuronales recurrentes para el
análisis de texto y de esta manera el modelo aprendía cual es la relación
entre una secuencia de palabras. Es decir, nosotros introduciríamos una secuencia
de palabras cómo Input y el modelo nos devolvería el sentimiento como Output.
Estaríamos delante de un esquema de aprendizaje supervisado
donde el ingeniero de turno se sentaría delante de la pantalla a valorar positiva
o negativamente un trillón de comentarios en la red para comenzar a entrenar el
modelo. Pero, ¿ qué ocurría si en lugar de una valoración Bueno / Malo pedíamos
al modelo una valoración numérica? Del 1 al 10, por ejemplo.
Pues lo que ocurría es que había que elaborar un nuevo dataset
desde cero. Daba igual lo parecida que fuera la nueva tarea a la anterior. Si
querías entrenar al modelo con una nueva tarea, requería de un nuevo dataset
concreto, y por tanto, de un nuevo entrenamiento.
El modelo ya era capaz de entender en su mayoría el mensaje de texto considerando giros interpretativos, sarcasmo o juegos de palabras, pero no dejamos de hablar de que cada modelo era entrenado para una tarea específica. Y no esta nada mal, son grandes avances, pero no sería hasta 2017 que presenciaríamos la verdadera carrera espacial en este nicho.
La era imagenet del NLP.
En 2017 viviríamos el verdadero “Bum” en la carrera por el Deep
Learning abriendo un camino prometedor en el campo de la Inteligencia
Artificial con los modelos generalistas multifuncionales. Se empezó a entrenar
a modelos que habían sido pre-entrenados en otras tareas y se amplió la
diversidad de fuentes de datos tomadas como Input.
No es lo mismo entrenar un modelo desde cero que reentrenar
un modelo que ya tiene datos; de la misma manera que no es lo mismo enseñar a
recitar poemas a un humano que no sabe leer frente a otro que sí. De esta
manera se lograba reducir la carga de trabajo y la cantidad de datos
necesarios.
Además, volviendo a la analogía con humanos, es más fácil para nosotros interpretar el mundo con los cinco sentidos que cuando somos privados de alguno de ellos. Cuando comemos una naranja, la sentimos al tacto, degustamos su sabor y somos capaces de olerla y verla. Podríamos vivir la experiencia privados de algún sentido, pero ¿verdad que la experiencia es más rica si se vive con más sentidos? Pues lo mismo ocurre con el Deep Learning, el aprendizaje es más rico cuanto mayor es la diversidad y el abanico de las fuentes de datos tomadas. Es más fácil para una máquina si puede nutrirse de datos de naturaleza textual o audiovisual que si solo lo hiciera de textos de la red.

Tu amigo transformer.
Coincidiendo con la llegada de los Transformers, en 2017 se
comenzó a pre-entrenar modelos de Inteligencia artificial para entender el
lenguaje. Y no… no estamos hablando de Optimus Prime y sus amigos sino de potentes
modelos AI basados en redes neuronales capaces de aprender contexto mediante el
seguimiento de datos secuenciales.
¿Y cómo conseguimos que una máquina aprenda nuestro
lenguaje? Pues de la misma manera que lo haría un niño: Le pondríamos
delante al modelo distintas oraciones y omitiríamos alguna palabra relevante
para que el modelo la complete. Coge esta idea y elévala al máximo exponente repitiendo
el proceso millones de veces hasta que aprenda finalmente a contextualizar el
lenguaje.
Al entrenar estos modelos conscientes de contexto ya no era
necesaria una supervisión por parte de Data Scientists.
La transición de un aprendizaje supervisado a un aprendizaje
auto-supervisado supuso un cambio del paradigma ya que, ya no era necesario
etiquetar manualmente nuestros datos, sino que podías desarrollar un proceso para
que estas etiquetas fueran generadas por el modelo y, como ya no era un problema
el etiquetado manual, estos modelos escalaban en magnitud de parámetros de
entrada exponencialmente.
Y no solo eso, si ya eres Data Scientist supongo que lo sabrás y si todavía no lo eres, pero te apasiona el sector, te encantará saber que las grandes corporaciones encargadas en desarrollar estos modelos los liberaban y ponían a disposición de la comunidad en la red donde tú podías coger estos modelos pre-entrenados y entrenarlos para tus propios fines. Una democratización del conocimiento sin precedentes que disparó la carrera tecnológica a un nuevo nivel de escalabilidad.
Modelos generativos pre-entrenados basados en transformers, GPTs.
Lo que se observó con estos modelos enormes que se nutrían
de todo tipo de datos en la red fue que, pretendiendo únicamente enseñarles a
entender nuestro lenguaje, aprendieron a realizar distintas tareas como generar
texto, hacer resúmenes, traducir a otras lenguas, sumar, restar y otras
operaciones matemáticas, actuar como un chatbot… Estamos hablando de los famosos
Modelos Generativos Pre-entrenados basados en Transformers, también conocidos
como GPTs.
En este punto, cabe destacar la aportación de Open AI al Deep
Learning en 2020: GPT-3. Hablamos de un modelo con 175 mil millones de parámetros
capaz de imitar la forma en la que los humanos nos comunicamos y no es de
extrañar. Imagina un modelo que ha aprendido tomando como base de datos todo lo
recogido en redes sociales. Y es que los avances en Inteligencia Artificial no
dejan de llamar a la puerta. En Mayo de 2022 se presentó de la mano de Deep
Mind: GATO. Gato, un modelo AI multimodal capaz de desempeñar 604 tareas con tan
solo 1,18 mil millones. Un modelo diminuto en comparación con gigantes como
GPT-3 ( 175 mil millones ), PaLM ( 540 mil millones ) o Chinchilla ( 70 mil
millones ). Quizás lo fascinante de este modelo no sea tanto el nivel de profundización
del modelo en cada una de las diferentes tareas (un nivel más que aceptable en
más de 450 de las tareas), sino la capacidad de ser pre-entrenado para hacer prácticamente
cualquier tarea con muy pocos datos en comparativa con otros de los enormes
modelos generalistas anteriores.
Y este es el punto en el que nos encontramos damas y caballeros, apenas crees haberte actualizado cuando de repente sale una nueva noticia que te golpea en la cara. Vivimos unos tiempos maravillosos en el ámbito de la Inteligencia Artificial y aquí en Nodd3r te iremos informando.