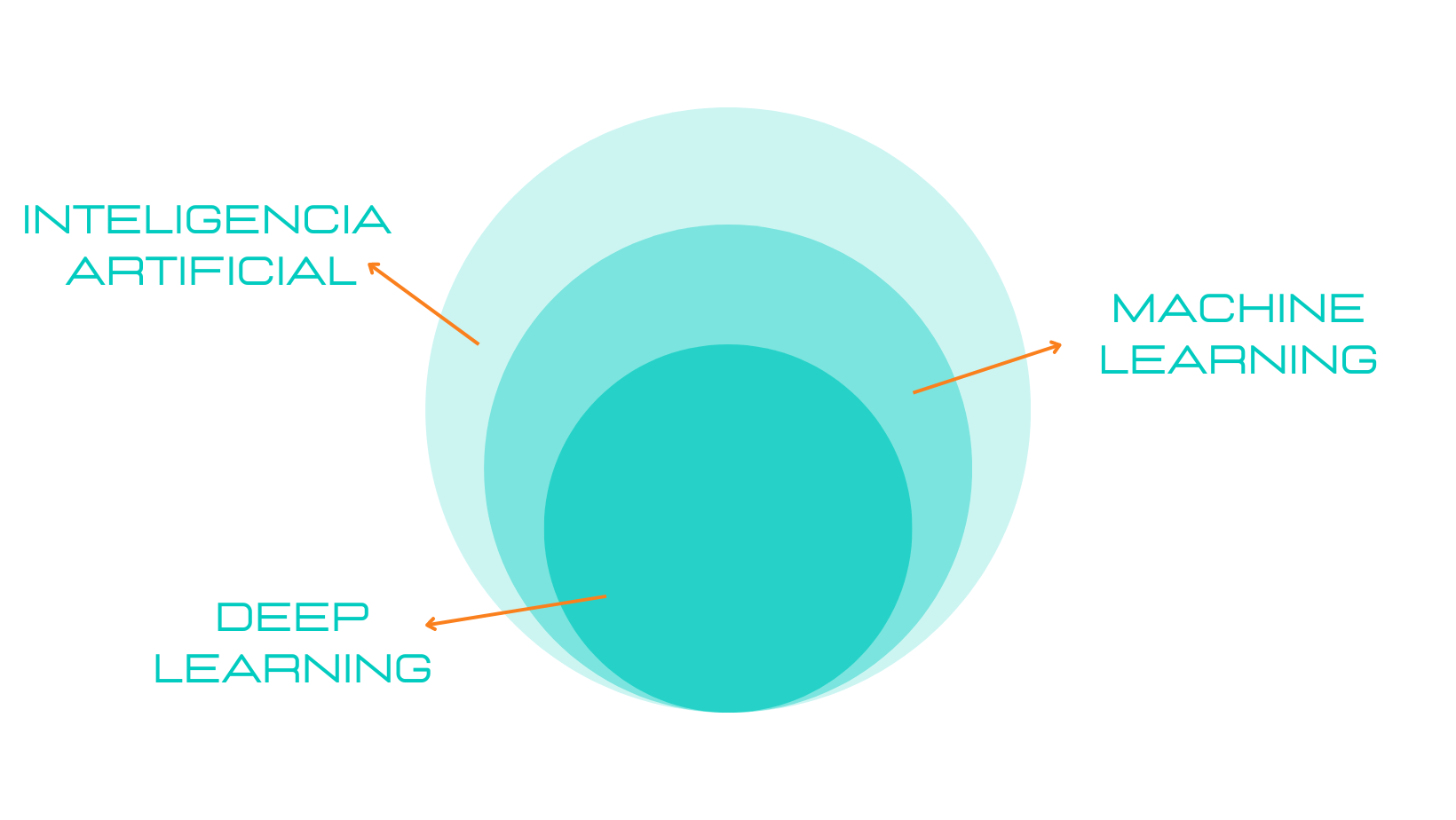
¿Cómo elegir el mejor modelo de machine learning?
Si estás pensando en crear un proyecto de machine learning, tienes que tener en cuenta que no siempre tener un modelo con mejor rendimiento será tu mejor solución.
En este blog te contaremos el por qué, a diferencia de lo que se cree, no siempre tu mejor opción entre varios modelos de machine learning, es el que tiene un mejor rendimiento.
Antes de nada, tenemos que tener en cuenta una cosa y es que, al igual que en la vida cotidiana, cuando tomas una decisión, ya sea de la índole que sea, tienes en cuenta distintos aspectos y eso ocurre también cuando decides qué modelo de machine learning se ajusta mejor a tus necesidades.
A continuación mencionaremos algunas de las consideraciones que se pueden tener en cuenta:
1. Rendimiento.
La calidad de los resultados del modelo es un factor fundamental a tener en cuenta a la hora de elegir un modelo. Es importante priorizar algoritmos que maximicen ese rendimiento.
Dependiendo del problema, diferentes métricas pueden resultar más útiles que otras para analizar los resultados del modelo. Por ejemplo, algunas de las métricas más populares son exactitud, precisión, recuperación y puntaje f1.
Y al igual que pasa con los modelos, no todas las métricas funcionan en todas las situaciones. Por ejemplo, la precisión no es adecuada cuando se trabaja con conjuntos de datos desequilibrados.
Seleccionar una buena métrica o conjunto de métricas para evaluar el rendimiento del modelo es una tarea crucial antes de seleccionar el modelo.
2. Explicabilidad.
En muchas ocasiones, explicar los resultados que genera un modelo es lo primordial. Desafortunadamente, muchos algoritmos funcionan como cajas negras y los resultados terminan siendo difíciles de explicar, independientemente de lo buenos que sean.
Por ejemplo, la regresión lineal y los árboles de decisión son buenos candidatos cuando la explicabilidad es un problema, sin embargo, las redes neuronales no tanto.
La falta de explicabilidad puede ser un factor decisivo en esas situaciones. Comprender cuánto de fácil o difícil será interpretar los resultados de cada modelo es importante antes de elegir uno.
Y resulta curioso pero la explicabilidad y la complejidad son dos aspectos que suelen estar en ambos extremos del espectro, por eso este último va a ser el siguiente que explicaremos.
3. Complejidad.
A pesar de que un modelo complejo puede encontrar patrones que quizás resulten más interesantes en los dados, estos serán más difíciles de mantener y explicar.
A la hora de decantarnos por un modelo complejo, hay que tener en cuenta estos dos aspectos:
- Una mayor complejidad puede conducir a un mejor rendimiento, pero también a mayores costos.
- La complejidad es inversamente proporcional a la explicabilidad, cuánto más complejo sea el modelo, más difícil será explicar sus resultados.
El costo de construir y mantener cualquier modelo es un factor crucial para conseguir un proyecto exitoso. Por eso, una configuración compleja tendrá un impacto cada vez mayor durante todo el ciclo de vida de un modelo.

4. Tamaño del conjunto de datos.
La cantidad de datos de entrenamiento disponibles es uno de los principales factores a considerar a la hora de elegir un modelo.
Un red neuronal es realmente buena para procesar y sintetizar toneladas de datos. Sin embargo, un modelo KNN (K-Nearest Neighbors), al ser un modelo sencillo y fácil de aplicar, funciona mejor con menos ejemplos.
Además, más allá de la cantidad de datos disponibles, también es necesario conocer cuántos datos necesita realmente el modelo para lograr buenos resultados. En ocasiones, se puede crear una gran solución con 100 ejemplos de capacitación, en cambio, otras veces se pueden necesitar 100.000.
5. Dimensionalidad.
Se puede observar la dimensionalidad de dos maneras diferentes: el tamaño vertical de un conjunto de datos representaría la cantidad de datos que tenemos y el tamaño horizontal sería el número de entidades.
Ambas dimensiones influyen en la selección de un buen modelo. Por ejemplo, en el caso de la dimensión horizontal, cuántas más características tenga, a menudo eso llevará al modelo a encontrar mejores soluciones.
Existe un fenómeno conocido como la maldición de la dimensionalidad que trataremos en otra ocasión para comprender mejor cómo la dimensionalidad afecta a la complejidad de un modelo.
No todos los modelos se escalan de la misma manera con conjuntos de datos de alta dimensión, algunos necesitan que se introduzcan algoritmos de reducción de dimensionalidad específicos cuando dichos conjuntos de datos de alta dimensión se convierten en un problema. Uno de los algoritmos más populares para esto es PCA (Principal Component Analysis).
6. Tiempo y costo de la capacitación.
Aquí es donde te lanzo las siguientes preguntas: ¿Cuánto tiempo lleva y cuánto cuesta entrenar un modelo? ¿Elegirías un modelo con una precisión del 98% cuyo entrenamiento cuesta $100.000 o un modelo con una precisión del 97% que cuesta $10.000?
Por supuesto, la respuesta dependerá de las prioridades que tengas establecidas inicialmente.
Equilibrar el tiempo, los costos y el rendimiento es crucial al diseñar una solución escalable.
Los modelos que necesitan incorporar nuevos conocimientos casi en tiempo real no pueden permitirse largos ciclos de formación. Por ejemplo, un sistema de recomendaciones que debe actualizarse constantemente con la acción de cada usuario se beneficia de un ciclo de capacitación económico.
7. Tiempo de inferencia.
Vuelvo a lanzarte otra pregunta: ¿Cuánto tiempo te lleva ejecutar un modelo y hacer una predicción?
En el caso de un sistema autónomo, este necesita tomar decisiones en tiempo real, por lo tanto, no se puede considerar ningún modelo que tarde demasiado en ejecutarse.
Por ejemplo, la mayor parte del procesamiento necesario para desarrollar predicciones utilizando KNN ocurre durante el tiempo de inferencia. Esto hace que sea costoso ejecutar. Sin embargo, un árbol de decisión será más ligero durante el tiempo de inferencia y requerirá más tiempo durante el entrenamiento.
CONCLUSIONES
Muchas veces las personas se fijan un modelo y lo hacen su favorito, ya que, por lo general, es el que mejor conocen y les dio buenos resultados en alguno de sus últimos proyectos.
Pero siento decir que no existe un modelo único que funcione en todas las situaciones, especialmente cuando consideramos las limitaciones de los sistemas de la vida real.
Comprender algunas de las diferentes consideraciones que se establecen a la hora de elegir un buen modelo es fundamental para garantizar un proyecto exitoso.
Y como resumen, aquí dejamos un listado de las consideraciones mencionadas anteriormente:
1. Rendimiento del modelo.
2. Explicabilidad de los resultados.
3. Complejidad del modelo.
4. Tamaño del conjunto de los datos.
5. Dimensionalidad.
5. Tiempo de entrenamiento y costo.
6. Tiempo de inferencia.