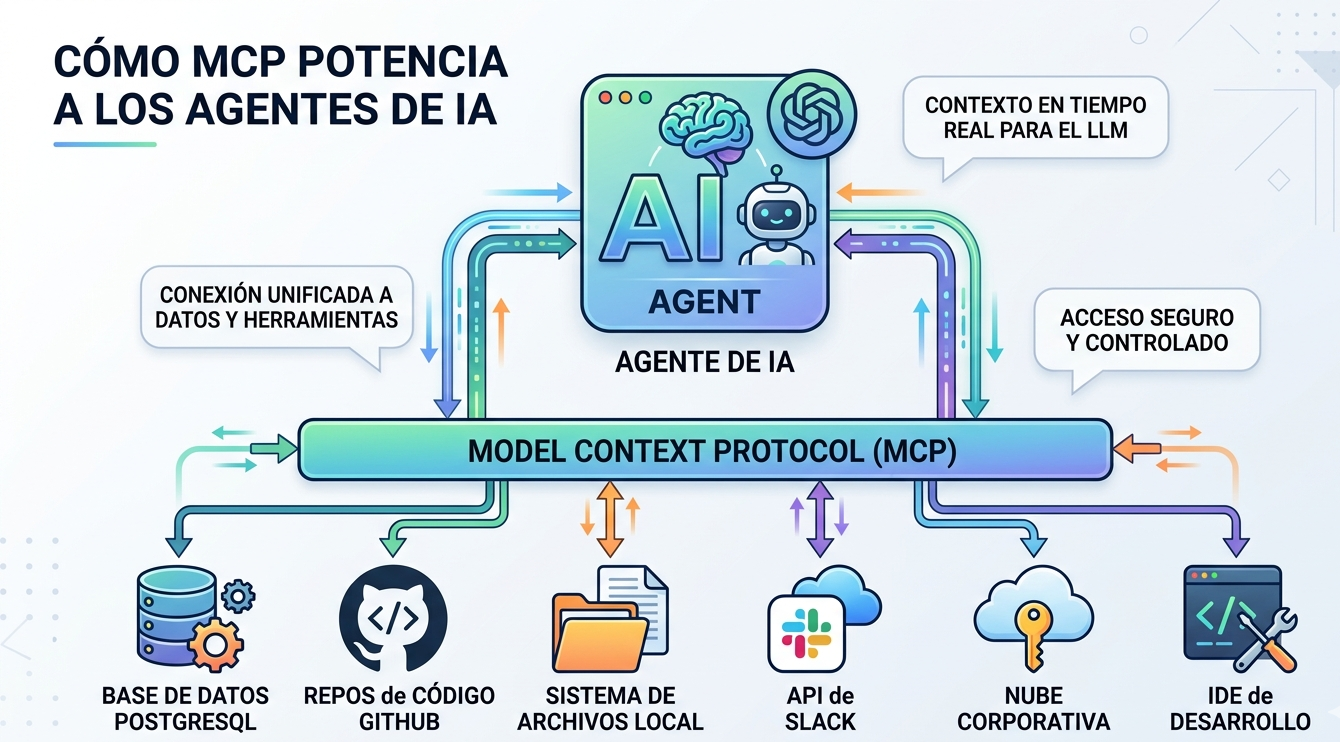
Historia del Data Science y la inteligencia artificial
Tanto la ciencia de datos como la inteligencia artificial se han encontrado a lo largo de la historia en una constante evolución, de ahí que estas tecnologías sigan desempeñando un papel cada vez más importante en la sociedad y economía.

La ciencia de datos o data science se encuentra estrechamente ligado con la inteligencia artificial, siendo dos de las tecnologías más revolucionarias de nuestra época.
Su evolución ha tenido un gran impacto en diferentes campos y sectores, desde la medicina hasta la publicidad online, teniendo en la actualidad un gran abanico de aplicaciones como: reconocimiento de voz, imágenes, sistemas de recomendación, etc.
Aunque no hay que dejar a un lado que tanto la ciencia de datos como la inteligencia artificial han planteado importantes cuestiones éticas y de privacidad, sobre todo en los últimos años.
¿Dónde está su origen?
Aunque parezca increíble, la historia de la ciencia de datos comienza en la década de 1940, gracias al matemático y estadístico John Tukey ya que se dedicaba a investigar nuevas formas de analizar grandes conjuntos de datos para encontrar patrones y tendencias, de ahí que acuñara el término "análisis exploratorio de datos".
En las décadas siguientes nacieron nuevas técnicas para analizar datos como el análisis de regresión, el análisis de componentes principales y el análisis de conglomerados.
En torno a 1950, los científicos comenzaron a trabajar con la tecnología de la inteligencia artificial.
J. McCarthy en 1956 organizó una conferencia en Dartmouth College (EE.UU.) en la que definió la inteligencia artificial como "la ciencia y la ingeniería de hacer máquinas inteligentes".
Fue cuando en 1962, John Tukey después de desarrollar algoritmos complejos y el diagrama de caja y bigotes, cuestiona el futuro de la estadística como ciencia empírica.

Tanto en la década de los 60 como los 70, la inteligencia artificial tuvo un gran impulso gracias al desarrollo de los ordenadores y los algoritmos.
Y no fue hasta 1974 cuando Peter Naur, un científico danés, acuñó el término de ciencia de datos a esa disciplina.
Unos años más tarde, la Asociación Internacional de Computación Estadística (IASC) en 1977 cuyo objetivo se centraba en vincular la metodología estadística tradicional con la tecnología informática moderna y el conocimiento de expertos en el dominio para convertir los datos en información y conocimiento se estableció como una sección del ISI (Institute for Scientific Information).
De ahí que la estadística comenzase a utilizarse para estudiar los datos y extraer información valiosa de los mismos.
Cabe destacar que durante los años 80, la inteligencia artificial experimentó una caída drástica en la popularidad debido a una serie de factores, entre ellos la falta de capacidad de procesamiento de los ordenadores y al dificultad que encontraban los profesionales para programar sistemas expertos.
Ya que hasta el momento sólo habían avanzado en lo que se conocía como "sistemas expertos", programas de ordenador diseñados para hacer tareas específicas que normalmente haría una persona en base al conocimiento humano para que pudiera tomar decisiones.
Por otro lado, cabe destacar que en la década de 1990 gracias al aumento de potencia de los ordenadores y al desarrollo de nuevas técnicas de aprendizaje automático, la inteligencia artificial recobró importancia.
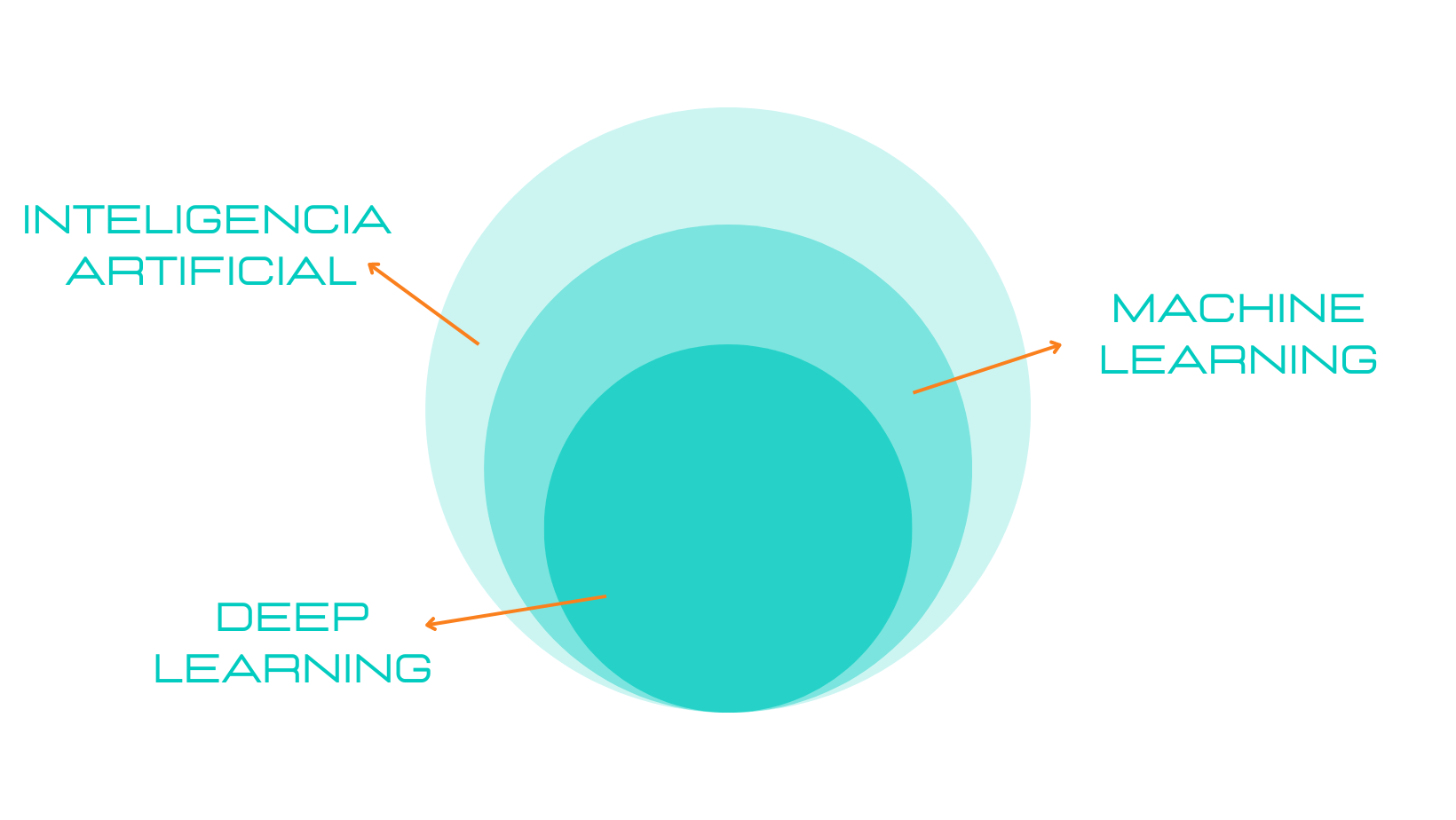
El aprendizaje automático también se conoce como machine learning es un campo de la inteligencia artificial que se encarga de construir algoritmos capaces de aprender de los datos.
Este tipo de algoritmos utilizan estadística y matemáticas para poder encontrar patrones de comportamiento en los datos y poder así, hacer predicciones.
En Japón durante el 1996 se reúne la Federación Internacional de Sociedades de Clasificación (IFCS) donde se incluye en el título de la conferencia por primera vez el término de "ciencia de datos".
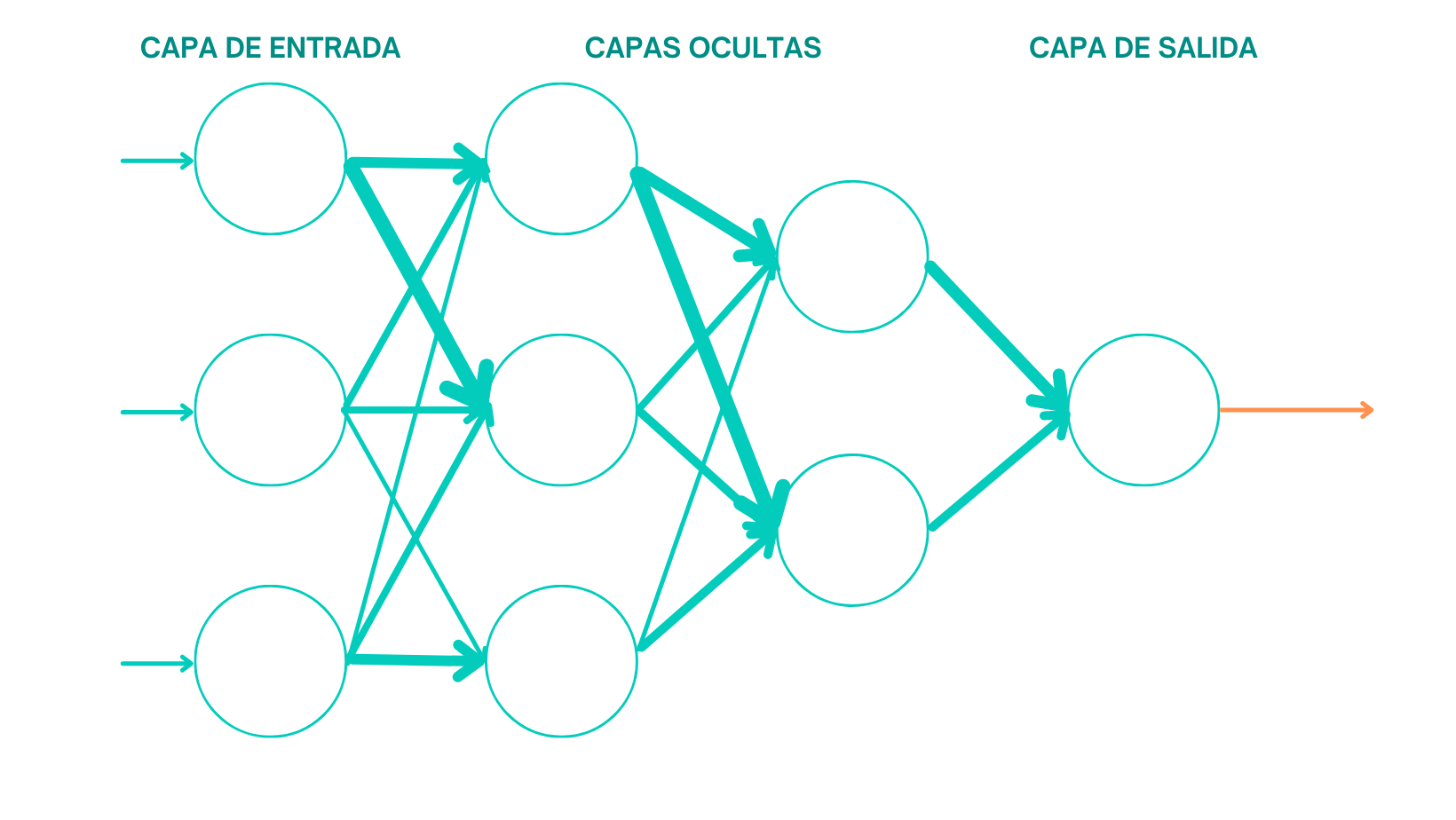
Ya en el 2000, con el deep learning o aprendizaje profundo se convierte en un campo de gran importancia dentro de la inteligencia artificial, ya que utiliza las redes neuronales artificiales.
Justo en 2001, William S. Cleveland, informático y estadístico estadounidense, presentó la ciencia de datos como una disciplina unificada y con independencia de la estadística. Y, al año siguiente, lanza Data Science Journal siendo la primera revista científica en lo referente a los datos.
A partir de esta década, la cantidad de datos que se generan diariamente han aumentado exponencialmente poniendo en el eje principal a la ciencia de datos y la inteligencia artificial.
La ciencia de datos se centra actualmente en la recolección, procesamiento y análisis de grandes conjuntos de datos.
Y la inteligencia artificial se encarga de la construcción de algoritmos que pueden aprender de los datos para poder realizar predicciones precisas.
Hoy por hoy, en la actualidad, ambas disciplinas están presentes en prácticamente cualquier sector o industria.
Listado de hitos relevantes de la ciencia de datos y la inteligencia artificial durante su evolución:
Algunos de los momentos más destacables de la historia de estas dos disciplinas son:
- 1943: Warren McCulloch y Walter Pitts publican un artículo en el que describen el primer modelo matemático de una red neuronal.
- 1956: John McCarthy, Marvin Minsky, Nathaniel Rochester y Claude Shannon organizan una conferencia en Dartmouth College en la que se acuña el término de "inteligencia artificial" por primera vez.
- 1959: Arthur Samuel escribe el primer programa de aprendizaje automático para jugar al juego de mesa "checkers" (damas).
- 1967: La empresa BNN desarrolla un sistema de procesamiento de lenguaje natural (NPL) "SHRDLU", capaz de responder preguntas y realizar tareas en un mundo virtual.
- 1974: Paul Werbos introduce el concepto de "retropropagación" como un método para entrenar redes neuronales profundas.
- 1981: Richard Sutton publica un artículo sobre el "aprendizaje por refuerzo", un enfoque en el que un agente aprende a través de la interacción con su entorno.
- 1986: Geoffrey Hinton, David Rumelhart y Ronald Williams desarrollan el algoritmo de "aprendizaje por refuerzo", un enfoque en el que un agente aprende a través de la interacción con su entorno.
- 1995: El software de minería de datos "WEKA" es lanzado por la Universidad de Waikato en Nueva Zelanda.
- 1997: La computadora "Deep Blue" de IBM derrota al campeón mundial de ajedrez Garry Kasparov en una serie de partidas.
- 2011: El sistema de inteligencia artificial "Watson" de IBM gana el concurso de televisión "Jeopardy!" al derrotar a dos campeones humanos.
- 2012: El sistema de aprendizaje profundo "AlexNet" de Geoffrey Hinton gana el concurso anual de reconocimiento de imágenes "ImageNet".
- 2014: La compañía de inteligencia artificial DeepMind de Google desarrolla el sistema de aprendizaje profundo "AlphaGo" que derrota al campeón mundial de Go, Lee Sedol.
- 2016: El algoritmo de clasificación de imágenes de Google, "Inception-v3", gana el concurso anual de reconocimiento de imágenes "ImageNet".
- 2018: La General Data Protection Regulation (GDPR) de la Unión Europea entra en vigor, estableciendo normas para la protección de datos personales de los ciudadanos.
- 2019: La compañía OpenAI lanza su sistema de lenguaje natural "GPT-2", que genera texto de manera automática y es capaz de pasar la prueba de Turing.
- 2020: La pandemia de COVID-19 impulsa el uso de la ciencia de datos y la inteligencia artificial en la investigación y la lucha contra la enfermedad.
- 2022: OpenAI lanza su sistema versionado de lenguaje natural "GPT-3" como "ChatGPT" de forma gratuita para que cualquier usuario pueda hacer uso del mismo.
En resumen:
La ciencia de datos y la inteligencia artificial no es nada nuevo ya que sus orígenes se remontan a décadas atrás pero sí es cierto que en los últimos años han experimentado un gran crecimiento.
Esto sobre todo se debe a la creciente cantidad de datos que se generan y acumulan, ya que aportan información muy valiosa y por ende, se necesitan de estas disciplinas para sustraerla.