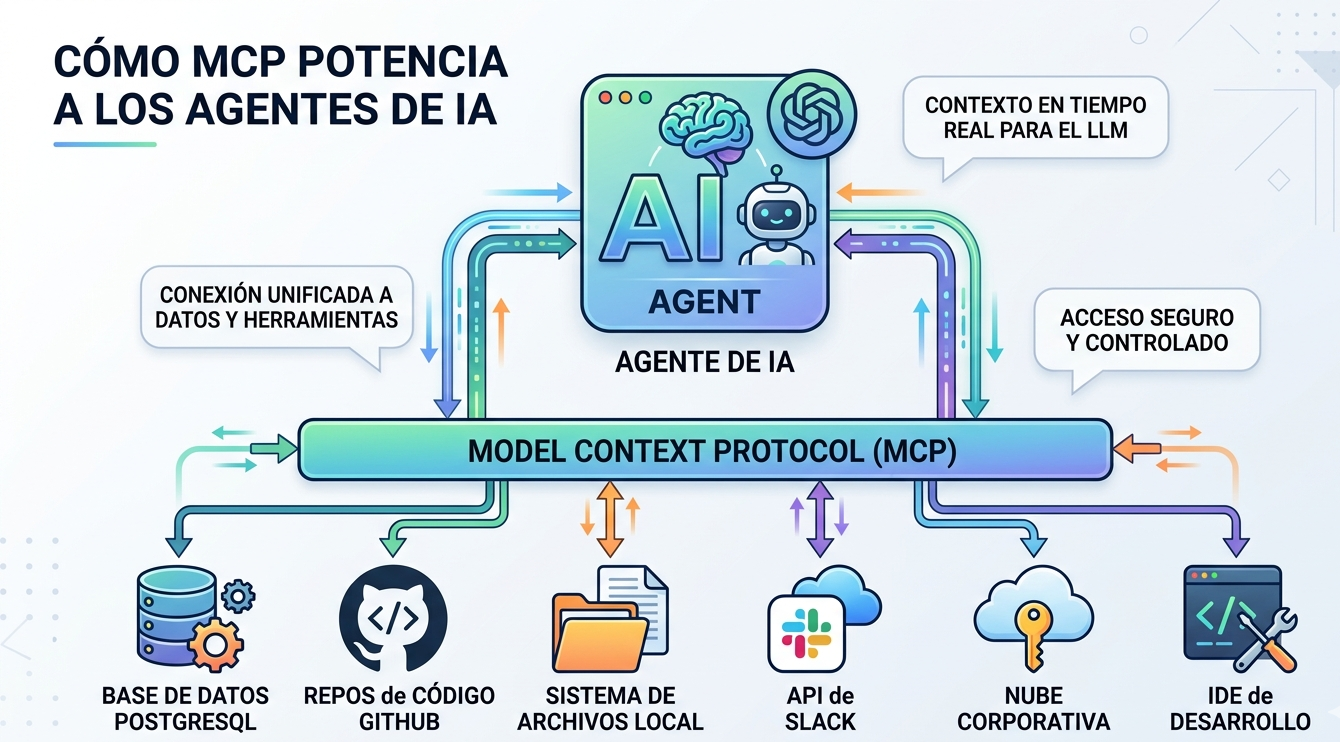
¿Cómo formarte como científico de datos desde cero?
Si no sabes qué necesitas para formarte como profesional en la ciencia de datos, aquí te dejamos una infografía para que comprendas mejor visualmente todo el proceso de formación y las etapas por las que pasarás hasta consolidarte como profesional cualificado.

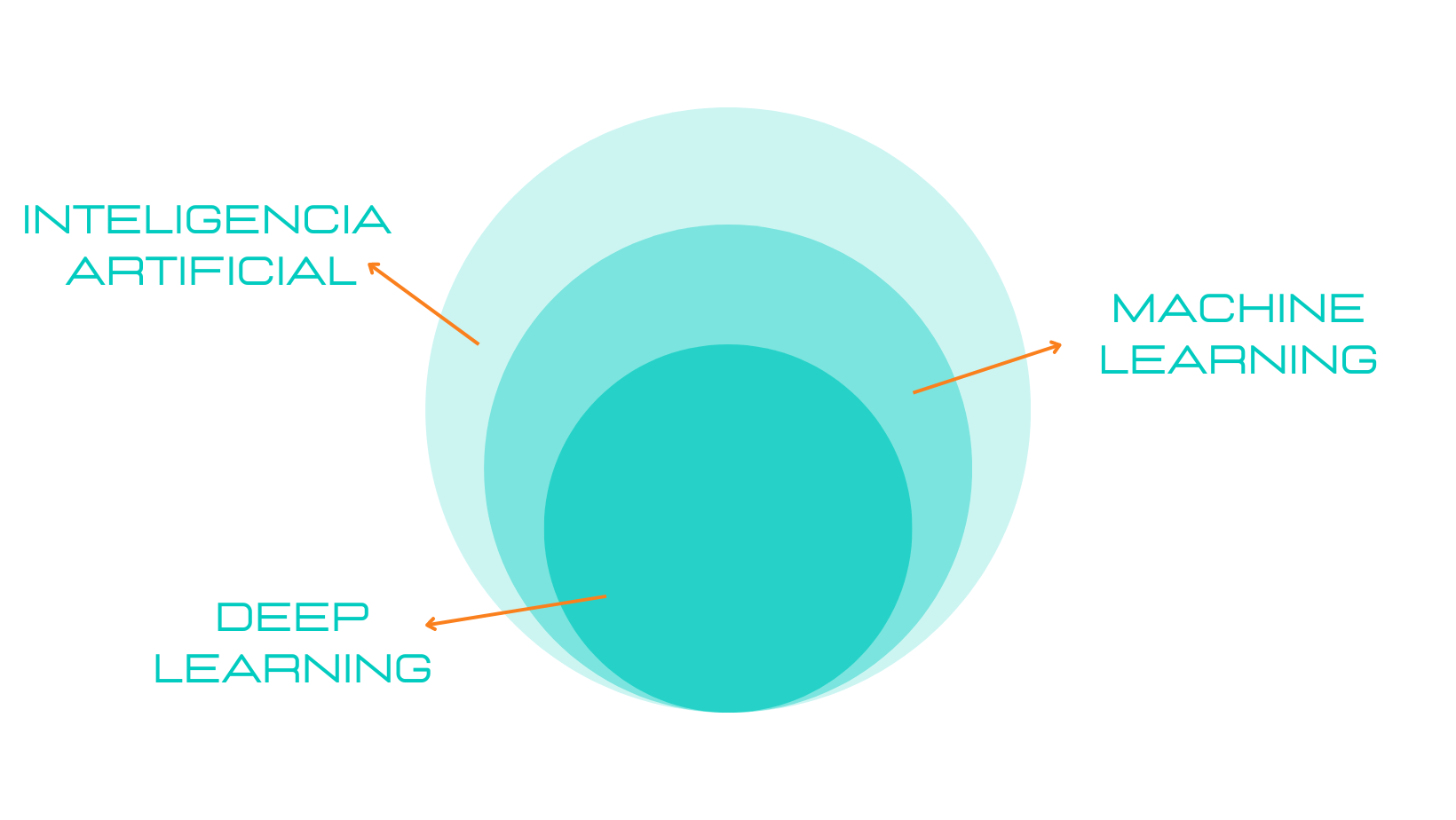
La ciencia de datos e inteligencia artificial son campos en constante crecimiento y con una demanda creciente de profesionales altamente capacitados.
Si te has preguntado alguna vez cómo se forma un data scientist desde cero y cuáles son los pasos clave para alcanzar el éxito en este campo, ¡has llegado al sitio correcto!
A continuación te explicaremos de forma detallada el camino para convertirte en experto en ciencia de datos e IA.
Paso 1: Fundamentos de matemáticas y estadística.
Todo gran científico de datos comienza adquiriendo y creando unas bases sólidas de conocimientos en matemáticas y estadística.
Estas bases son esenciales para comprender los conceptos fundamentales y algoritmos que sustentan la ciencia de datos.
Los conceptos principales se podrían agrupar en:
- Álgebra y cálculo:
Tendrás que aprender los conceptos matemáticos fundamentales como álgebra lineal y cálculo diferencial e integral. Estas bases te permitirán comprender conceptos más avanzados dentro de la ciencia de datos como el álgebra de matrices y las derivadas parciales utilizadas en algoritmos de machine learning.
- Probabilidad y estadística descriptiva:
Con esto obtendrás una comprensión sólida de la teoría de la probabilidad y aprenderás a analizar datos mediante estadísticas descriptivas, como medidas de tendencia central, dispersión y correlación.
- Estadística inferencial:
La inferencia estadística y las técnicas para hacer predicciones y tomar decisiones basadas en muestras de datos lo aprenderás aquí.
Paso 2: Programación y lenguajes de programación.
En este paso aprenderás a dominar la programación y a trabajar con lenguajes ampliamente utilizados en el análisis de datos y la IA.
Gracias a saber dominar estos lenguajes podrás manipular datos, implementar algoritmos de aprendizaje automático y crear visualizaciones interactivas.
- Introducción a la programación:
Iniciarás con conceptos básicos de programación como variables, operadores y estructuras de control.
También aprenderás a resolver problemas sencillos utilizando la lógica de programación.
- Python y R:
Estos son los dos lenguajes de programación más utilizados dentro de la ciencia de datos, de hecho, Python es el más demandado por las empresas cuando buscan profesionales.
En este punto conocerás las bibliotecas y módulos específicos de cada lenguaje que facilitan el análisis de datos y la implementación de algoritmos de IA.
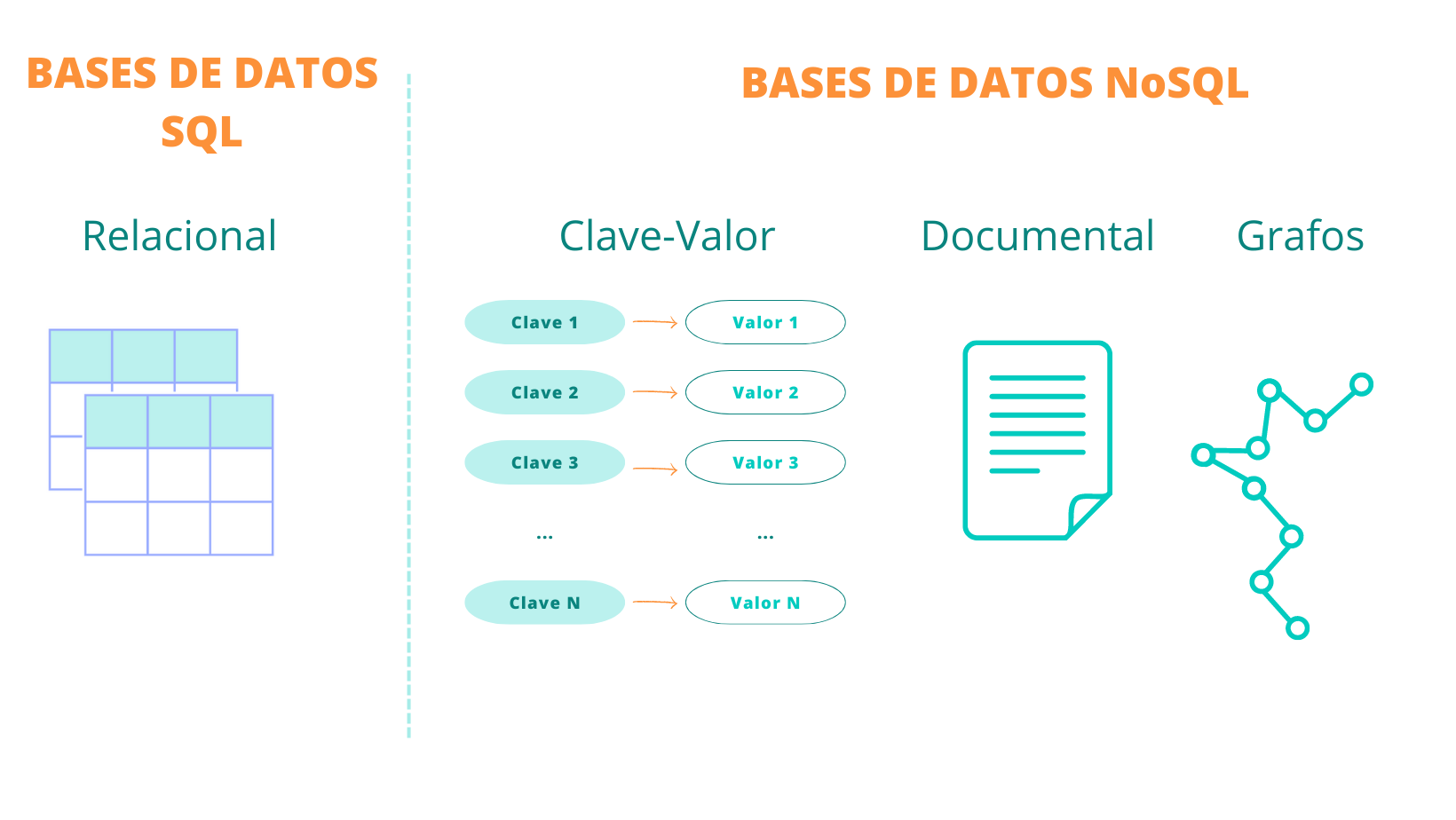
Paso 3: Bases de datos y SQL.
Dominarás el manejo de bases de datos y el lenguaje SQL, para extraer, gestionar y analizar grandes conjuntos de datos.
- Conceptos de bases de datos:
Comprenderás la estructura y los tipos de bases de datos, así como los sistemas de gestión de bases de datos más comunes.
- Diseño de bases de datos:
Aprenderás a diseñar bases de datos relacionales, definiendo tablas, claves primarias y relaciones entre ellas.
- SQL:
Dominarás el lenguaje SQL, que te permitirá realizar consultas complejas para extraer, filtrar y analizar datos desde una base de datos.

Paso 4: Análisis de datos y visualización.
En este paso, te sumergirás en el mundo del análisis de datos, adquiriendo las habilidades para explorar, limpiar y analizar datos, utilizando técnicas estadísticas y herramientas de visualización.
La visualización de datos es crucial para comunicar resultados y patrones de manera efectiva a audiencias no técnicas.
- Análisis exploratorio de datos (EDA):
Aprenderás a explorar y entender los datos mediante técnicas como gráficos, estadísticas descriptivas y visualizaciones preliminares.
- Limpieza de datos:
Desarrollar las habilidades para limpiar y procesar datos, eliminar valores faltantes, detectar y corregir errores y normalizar datos para su posterior análisis es fundamental.
- Técnicas de visualización:
Dominarás herramientas y bibliotecas de visualización, como Matplotlib y Seaborn en Python, para crear gráficos informativos y atractivos que ayuden a comunicar tus hallazgos de manera efectiva.
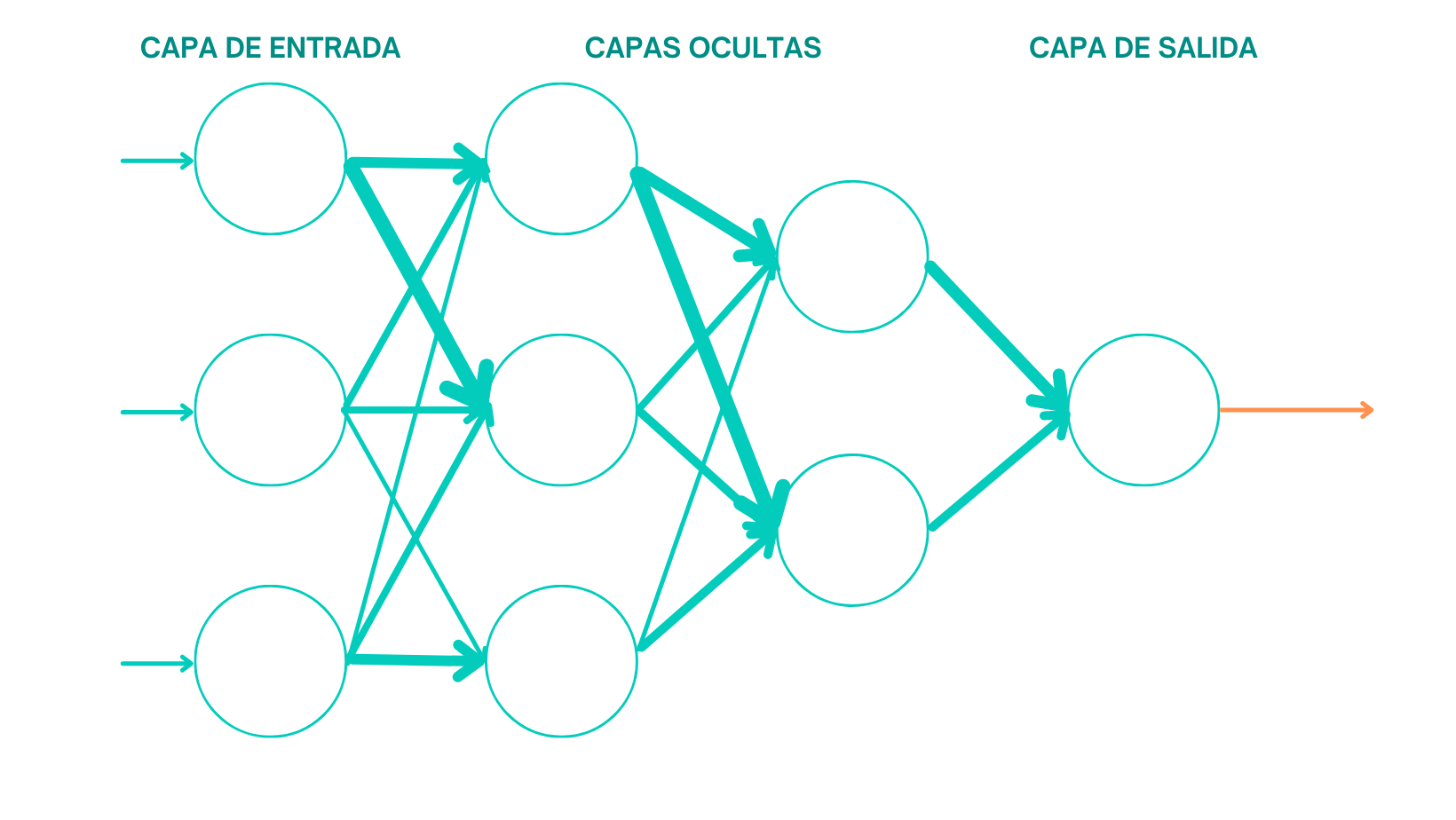
Paso 5: Aprendizaje automático (Machine Learning)
Uno de los pilares centrales de la ciencia de datos es el aprendizaje automático.
Aquí profundizarás en algoritmos, modelos predictivos y técnicas de entrenamiento. Además, comprenderás conceptos como la regresión, la clasificación, agrupación y métodos de evaluación de modelos.
- Tipos de aprendizaje automático:
Aprenderás los conceptos básicos de aprendizaje supervisado, no supervisado y por refuerzo, comprendiendo cómo funcionan y en qué situaciones se aplican.
- Preprocesamiento de datos para aprendizaje automático:
Aprenderás a preparar los datos para entrenar modelos de aprendizaje automático, realizando tareas como codificación de variables categóricas y normalización de características.
- Modelos de aprendizaje automático:
Estudiarás algoritmos populares como regresión lineal, máquinas de soporte vectorial, k-means y árboles de decisión, así como técnicas de evaluación de modelos para seleccionar el mejor modelo para un problema específico.
Paso 6: Proyectos prácticos.
A lo largo de tu formación, deberás llevar a cabo proyectos prácticos que te permitirán aplicar lo que has aprendido.
Estos proyectos te desafiarán a resolver problemas reales, enfrentarás conjuntos de datos complejos y trabajarás en equipo para obtener soluciones sólidas.
- Identificación de problemas reales:
Seleccionarás problemas y desafíos del mundo real para abordar con tus nuevas habilidades. Estos pueden incluir pronósticos de ventas, análisis de sentimientos en redes sociales o detección de fraudes.
- Adquisición de datos:
Aprenderás a recopilar datos relevantes para tus proyectos a través de diversas fuentes como APIs, bases de datos o web scraping.
- Exploración y análisis:
Realizarás análisis exploratorios de datos para comprender la estructura y las relaciones dentro del conjunto de datos y definir los enfoques adecuados para el problema.
- Modelado y evaluación:
Implementarás y evaluarás diferentes modelos de aprendizaje automático para resolver el problema en cuestión, afinando los hiperparámetros y optimizando el rendimiento.
- Comunicación de resultados:
Presentarás tus hallazgos y resultados de manera clara y concisa a audiencias técnicas y no técnicas, demostrando el valor y la aplicabilidad de tus soluciones.
Paso 7: Herramientas y frameworks.
En el mundo de la ciencia de datos existen una gran cantidad de herramientas y frameworks que facilitan el trabajo diario.
Te familiarizarás con algunas de las más populares como TensorFlow, PyTorch o Scikit-Learn y aprenderás a utilizarlas para acelerar tus proyectos y análisis de datos.
- TensorFlow:
Es una biblioteca de código abierto desarrollada por Google para la creación y entrenamiento de modelos de aprendizaje profundo (deep learning).
- PyTorch:
Es otra popular biblioteca de aprendizaje profundo que ha ganado terreno en los últimos años dentro de la comunidad de investigación de la inteligencia artificial.
- Stickit-learn:
Esta es una biblioteca de aprendizaje automático en Python que ofrece una amplia variedad de algoritmos y utilidades para tareas de clasificación, regresión y agrupación.
En conclusión:
Con todos estos pasos podrás convertirte en un científico de datos desde cero.
Aquí entra en juego tu dedicación y pasión por aprender esta disciplina lo antes posible.
Además, como data scientist, tendrás la oportunidad de trabajar en múltiples industrias y contribuir al desarrollo de soluciones innovadoras basadas en datos.
Recuerda que cada paso del camino es crucial y no hay atajos para el éxito en este campo.
Ahora, si lo que quieres es tener a alguien que te acompañe en todo el proceso, te guíe y te aconseje mejor, puedes contactar con nosotros y veremos si podemos ayudarte.